
We migrated 1.3 million items from Plone to Django
How to solve problems with timezones, broken data, incorrect data, missing persons, inconsistent data, etc. We outline our general approach.
Import script 3759 lines of code
Exporting was easy. Importing needed a mapping file to combine HRS1 and HRS2 fields together which contains 3759 lines of code, not optimized in any way of course because it is a one time job. Lots of inline comments and try except in try except to prevent errors en fix broken data. That all aside here is what has been done.
The total process
The whole process takes about 50 hours. This is cut into three segments. Export, Import, Prep production. While export/import take both about 20 hours, prep production is done in ten. So we only need three days and no night work to complete the full task. Starting at Friday 9:00 sharp. Export is done before 9:00 on Saturday and import is done before 9:00 on Sunday. As you see no sleep is lost. And it was absolutely unnecessary to put effort in optimizing both export and import as it would only make sense if we could cut them in half which was something we never thought would be possible so we didn't even try.
For the import there were several optimizations done, as first runs would take up to 5 days. Back in the days way before any Corona on a Friday evening at the bar at Four Digits we had a look at the running queries during the import;
SELECT * FROM pg_stat_activity
When it became clear that adding just a few indexes to our database would significantly optimize the import time. The reason was that before every object was created we did several get checks in the database to ensure data integrity.
The pre production phase is copying data to the production environment and doing manual checks and changes. Probably something we could have optimized even more but no need to rush as go live is planned on Monday 9:00.
Exporting from Plone
Export is done by using: https://github.com/collective/collective.jsonify easy to use, and fully documented https://collectivejsonify.readthedocs.io/en/latest/#using-the-exporter.
Only 2 paths were skipped, as they were unrelated for the import: membrane_tool and portal_postcode some Plone portal tools.
return export_content_orig(
self,
basedir='/tmp', # absolute path to directory for the JSON export
skip_callback=lambda item: False, # optional callback. Returns True to skip an item. # noqa
extra_skip_classname=[], # optional list of classnames to skip
extra_skip_paths=['membrane_tool', 'portal_postcode'],
# batch_start=0,
# batch_size=5000,
# batch_previous_path='/absolute/path/to/last/exported/item'
)
One other thing we did was add a lot of ComputedFields within the current codebase. This made it easier to map version 1 data to version 2. As ComputedField are being export as its own field in Json.
ComputedField(
name='coordinatoren_uid',
widget=ComputedField._properties['widget'](
visible={'view': 'invisible', 'edit': 'invisible'},
label='coordinatoren_uid',
),
mode='rw',
expression="context._getMijnCoordinatorUID()",
accessor="context._getMijnCoordinatorUID()",
edit_accessor="context._getMijnCoordinatorUID()",
),

Lots of data, time consuming
1324 directories
root@serverx:/tmp/content_portaal-nl_2020-04-17-13-09-35# ls
0 1029 1060 1092 1123 1155 1187 1218 125 1281 1312 152 184 215 247 279 31 341 373 404 436 468 5 530 562 594 625 657 689 72 751 783 814 846 878 909 940 972
1 103 1061 1093 1124 1156 1188 1219 1250 1282 1313 153 185 216 248 28 310 342 374 405 437 469 50 531 563 595 626 658 69 720 752 784 815 847 879 91 941 973
10 1030 1062 1094 1125 1157 1189 122 1251 1283 1314 154 186 217 249 280 311 343 375 406 438 47 500 532 564 596 627 659 690 721 753 785 816 848 88 910 942 974
100 1031 1063 1095 1126 1158 119 1220 1252 1284 1315 155 187 218 25 281 312 344 376 407 439 470 501 533 565 597 628 66 691 722 754 786 817 849 880 911 943 975
1000 1032 1064 1096 1127 1159 1190 1221 1253 1285 1316 156 188 219 250 282 313 345 377 408 44 471 502 534 566 598 629 660 692 723 755 787 818 85 881 912 944 976
...
1027 1059 1090 1121 1153 1185 1216 1248 128 1310 150 182 213 245 277 308 34 371 402 434 466 498 529 560 592 623 655 687 718 75 781 812 844 876 907 939 970
1028 106 1091 1122 1154 1186 1217 1249 1280 1311 151 183 214 246 278 309 340 372 403 435 467 499 53 561 593 624 656 688 719 750 782 813 845 877 908 94 971
1000 files each
root@serverx:/tmp/content_portaal-nl_2020-04-17-13-09-35/29# ls
29000.json 29056.json 29112.json 29168.json 29224.json 29280.json 29336.json 29392.json 29448.json 29504.json 29560.json 29616.json 29672.json 29728.json 29784.json 29840.json 29896.json 29952.json
29001.json 29057.json 29113.json 29169.json 29225.json 29281.json 29337.json 29393.json 29449.json 29505.json 29561.json 29617.json 29673.json 29729.json 29785.json 29841.json 29897.json 29953.json
29002.json 29058.json 29114.json 29170.json 29226.json 29282.json 29338.json 29394.json 29450.json 29506.json 29562.json 29618.json 29674.json 29730.json 29786.json 29842.json 29898.json 29954.json
29003.json 29059.json 29115.json 29171.json 29227.json 29283.json 29339.json 29395.json 29451.json 29507.json 29563.json 29619.json 29675.json 29731.json 29787.json 29843.json 29899.json 29955.json
29004.json 29060.json 29116.json 29172.json 29228.json 29284.json 29340.json 29396.json 29452.json 29508.json 29564.json 29620.json 29676.json 29732.json 29788.json 29844.json 29900.json 29956.json
...
29054.json 29110.json 29166.json 29222.json 29278.json 29334.json 29390.json 29446.json 29502.json 29558.json 29614.json 29670.json 29726.json 29782.json 29838.json 29894.json 29950.json
29055.json 29111.json 29167.json 29223.json 29279.json 29335.json 29391.json 29447.json 29503.json 29559.json 29615.json 29671.json 29727.json 29783.json 29839.json 29895.json 29951.json
As there were 1.3 million items, and all in a json file. We created an index file to store basic information about Type and Path so we could split the importer based on a content-type or path only. This way we didn't have to wait for the computer to open and close 1.3 million items when only 20.000 where needed.
def create_index_file(self, path, index, filepaths, paths, limit):
for dirpath, dirnames, filenames in os.walk(path):
logger.info("{}/{}".format(index, dirpath.split("/")[-1]))
index += 1
for filename in filenames:
with open("{}/{}".format(dirpath, filename), "r") as json_file:
try:
data = json.load(json_file)
except:
logger.info(f"cannot load {json_file}")
pass
else:
if data:
paths[data["_path"]] = {
"_type": data["_type"],
"_uid": data["_uid"],
"_filename": "{}/{}".format(
dirpath.split("/")[-1], filename
),
}
if data["_type"] in filepaths.keys():
filepaths[data["_type"]].append(
"{}/{}".format(dirpath.split("/")[-1], filename)
)
else:
filepaths[data["_type"]] = [
"{}/{}".format(dirpath.split("/")[-1], filename)
]
if index > limit:
break
with open(path + "/listfile.txt", "w") as filehandle:
filehandle.write(str(filepaths))
with open(path + "/pathfile.txt", "w") as filehandle:
filehandle.write(str(paths))
return paths
We now have a listfile.txt and pathfile.txt based on the export information. This would take about 40 minutes to create and only 2 minutes to load in memory when starting a new importer. This way we could export once, create the index files and then retry importing and only have a 2-minute setback when something was wrong.
Also, we completely split up all content so everything could run separately. A dump was made after each step so going back and forth was absolutely possible.
[19/Apr/2020 00:53:22] INFO [website.management.commands.import_from_json:3409] Count: 551749
[19/Apr/2020 00:53:22] INFO [website.management.commands.import_from_json:3411] Dumping Note
[19/Apr/2020 00:55:04] INFO [website.management.commands.import_from_json:3421] Done tmp/Aantekening_Note.pgsql.gz
Importing json to Django
The importing process needed a mapping between the created json file and the new HRS2 database. As HRS1 was in dutch and HRS2 is written in english we get something like:
zip_code = afdeling_postcode.
A small part of the complete mapping:
"Persoon": [
{
"class": Profile,
"field_mapping": {
"_uid": "_uid",
"first_name": "persoon_voornaam",
"last_name_prefix": "persoon_tussenvoegsel",
"last_name": "persoon_achternaam",
"email": "email",
"address_street": "persoon_straat",
"address_number": "persoon_huisnummer",
"address_number_ext": "persoon_huisnummer_toevoeging",
"zip_code": "persoon_postcode",
"city": "persoon_plaats",
},
},
],
"Afdeling": [
{
"class": Area,
"field_mapping": {
"_uid": "_uid",
"_original_id": "id",
"title": "title",
"name": "afdeling_naam",
"description": "description",
"code": "afdelingscode",
"address_number_ext": "afdeling_huisnummer_toevoeging",
"zip_code": "afdeling_postcode",
"city": "afdeling_plaats",
"type": "Department",
"address_street": "afdeling_postadres",
"address_number": "afdeling_huisnummer",
"cost_heading": "kostenplaats",
"provinces": "afdeling_provincie",
"telephone": "afdeling_telefoonnummer",
"email": "afdeling_email",
"sync_intranet_and_website": "sync_to_ki",
},
}
],
Import was cut into six steps as some content needed to be created first then linked the be filled with more data and so on.
Timezones
First my personal favourite, timezones: time, dates, datetime, now and today. Everything was incorrect in Plone.
def to_timezone(self, obj):
import pytz
from pytz import timezone
# Make a timezone aware datetime object from a datetime object.
return timezone("Europe/Amsterdam").localize(obj).astimezone(pytz.UTC)
def from_zope_date(self, obj, data, field, value):
if data[value] and not data[value] == "None":
setattr(
obj, field, self.to_timezone(parser.parse(data[value], ignoretz=True))
)
return obj
def created(self, obj, data, field, value):
return self.from_zope_date(obj, data, field, value)
An activity has an start and end date. Even with all protections in place, there were for example 12 projects having a startdate AFTER the enddate. Same for Links, Volunteers and Participants.
def end(self, obj, data, field, value):
end_date = data[value]
start_date = data["startdatum"]
if end_date < start_date:
uid = data["_uid"]
logger.info(
f"{obj} {uid} has end: {end_date} before start: {start_date}"
)
data["einddatum"] = start_date
return self.from_zope_date(obj, data, field, value)
Missing users
Content was created by a user, but the user was deleted (mostly LDAP users). This means there was no way to link that content again to its give owner in Django as the foreign key could not be made to a nonexistent user.
def get_user(self, obj, data, field, value):
for username in data.get(value, None):
try:
user = get_user_model().objects.get(username=username)
except get_user_model().DoesNotExist:
# be quiet for now, as we are missing tons of users mainly ldap users
# we do a retry based on creator in same project.
creator = data.get("creator", None)
if creator:
creator = creator.split(" ")[0]
project_code = data["_path"].split("/")[3]
project = Project.objects.get(code=project_code)
pv = ProjectVolunteer.objects.filter(
project=project,
volunteer__profile__first_name=creator,
)
if pv.count() == 1:
pv = pv.first()
user = pv.volunteer.profile.user
setattr(obj, field, user)
pass
else:
setattr(obj, field, user)
return obj
Usernames and Passwords
Passwords were only missing a bcrypt$ in front of the current bcrypt passwords. They all kept working fine.
try:
validate_email(data["email"])
email = data["email"]
except forms.ValidationError:
email = "" # empty when garbage
if "password" in data.keys() and data["password"]:
password = "bcrypt$" + data["password"]
else:
password = "Super-Secret"
How to get the project done
This was not a project done in a few days. It took over 15 months of development and over 6000 commits and 1660 pullrequests.
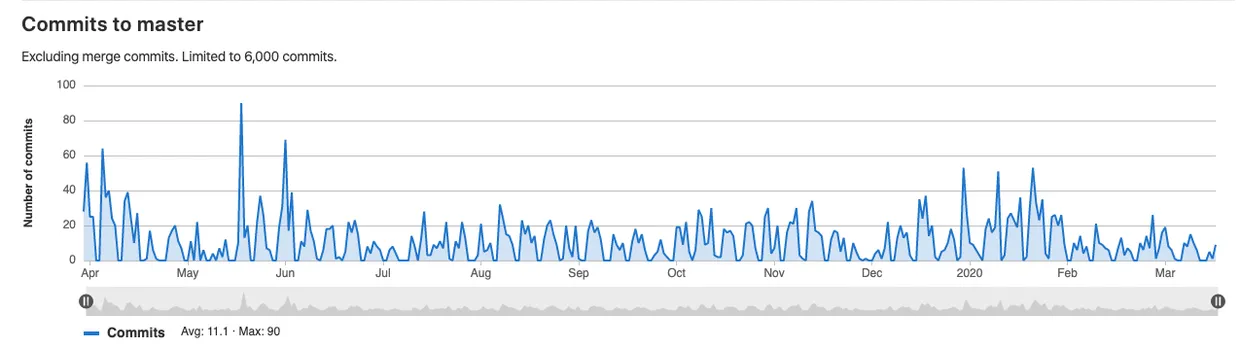
In total 16 contributors worked on it, not only during work hours and days, as you can see in this image. There is no way to describe the effort our team made during this project. The frontend is kickass, when you add a field in the backend you don't have to worry about layout. That way backend development could completely focus on the task at hand.
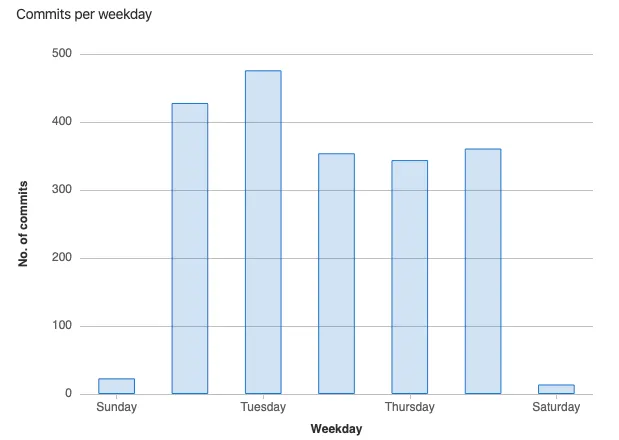
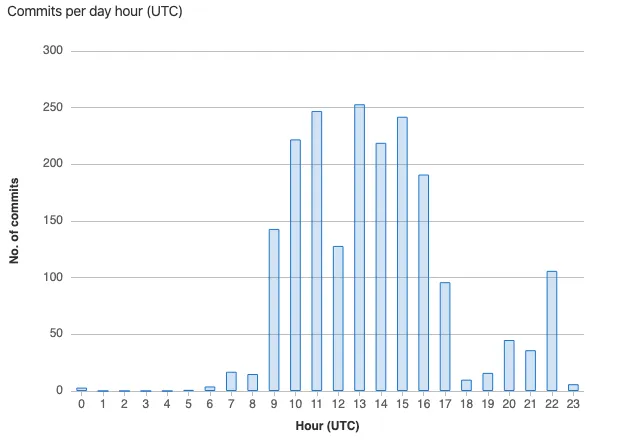
We have commits on 22:00 in the evening and on Saturday and Sunday. Mainly because people were excited they could fix something and get the project to another level. The importer ran every day and if it would crash late in the evening a fix would be made so we could continue the next morning, and so on.
We programmed 72% Python, 23% HTML, 2.5% JS 2.5% CSS.
Starting on Friday
There were several steps to take before we could start the export. Stop the current website, change DNS to show http://hrs.humanitas.nl/hoera/ etc. After the GO from team stopping HRS1 we could start copying data to our export/import setup. This data copy took about 4 hours, as the total size was 164GB.
Export took about 20 hours. Not bad to export 1.324.441 items from Plone. This created the same amount of json files on disk having a total size of 110GB. As this process was taking about 24hours in total, we didn't have to set any alarms for the next day.
Importing on Saturday
Around 9:00 pm export was done and we could start an easy day in the process. Just follow the script.
ssh serverX
cd /home/hrs/
rm -Rf media/*
rm -Rf private/*
rm -Rf tmp/*
sudo su postgres
dropdb hrs2-import
createdb hrs2-import
exit
git pull
python manage.py migrate
python manage.py assign_permissions
screen
python manage.py import_from_json /tmp/content
Terminal 2:
tail -f /home/hrs/tmp/logfile.txt
And again wait 18 hours. This process would create all the necessary content in de Django. Everything tested on beforehand and we cleaned garbage along the way.
Working on Sunday
Time to move data again. From the export/import environment to the new production location. We had a script in place to follow. Data has shrunk to 800mb database file (29GB in Plone) and around 80gb of files. In this step we checked, rechecked and made sure everything was working. After a few hours (5), we were done. The pipelines where pushed to production and everything was in place.
Live on Monday
Big day, we removed the ip-restriction from hrs.humanitas.nl and the log in page was shown to everyone who tried to log in. We celebrated, using video conferencing due to corona. Sad as we made big plans in February. The party will follow another time.
Everything is up-and-running. We are happy, it's time for a small break. And then we start in about two weeks on HRS2.1. Including many many new requested features. Yep, software is never done. Let's hope we can wait another +10 years for the next migration.
Thanks to my team, Dennis from Dezzign, Joost from Goed Idee Media, many others and of course team Humanitas for testing, feedback, projectsupport and giving us the power and opportunity to create HRS2!
:wave:

